![[Your logo here]](media/logo.jpg)
WG1: Encoding Proposals
Who am I?
I am Lou Burnard, now on my third or fourth life.
- I was born on the same day as the poet John Milton, but approx 300 years later. I studied at Oxford University, with a masters in English Studies, specialising in 19th century literature in 1971
- After which I taught World Literature in the University of Malawi for a couple of years
- For about 25 years I worked at Oxford University Computing Services, initially as a data centre operator, eventually as Assistant Director
- I started the Oxford Text Archive in 1976; the Text Encoding Initiative in 1987; the British National Corpus in 1994;
- In 2010 I took early retirement from OUCS and started work as a freelance
- Between 2009 and 2012 I worked closely with the TGE Adonis which eventually became HumaNum, the French digital humanities infrastructure
Look me up on Google if you get bored during the rest of this talk...
Proposed Encoding Guidelines for the ELTeC
A discussion document setting out the full proposal is available here
We summarize the proposals as follows:
- Use TEI XML : a well-established, customizable, scholarly standard
- Capture a guaranteed minimum of features for each text:
- significant structural features (chapters, headings, paragraphs...)
- descriptive metadata (bibliographic and non bibliographic)
- The proposal raises a number of open questions as to which features should be captured
- The proposal defines an XML schema and a set of rules which can be used to validate converted texts (more or less) automatically
What sort of guaranteed minimum?
The focus is not to represent texts in all their original complexity of structure or appearance, but rather to facilitate a richer and better-informed distant reading than a transcription of its lexical content alone would permit.
For example,
- to distinguish headings and annotations from the rest of the text
- to be able to locate stretches of text within gross structural features such as chapters and paragraphs
- to distinguish narrative voices (?)
Why XML-TEI?
Why not just use plain text?
- By using an XML based format, we ensure that
- ELTeC texts can be validated
- ELTeC texts can be converted to other formats using simple widely-available technologies
- ELTeC texts can be enriched with additional more sophisticated annotations
- By using TEI, we can take advantage of tools and techniques, widely used across the research community likely to be interested in the ELTeC
- NB Using the TEI does not mean our encoding will represent every possible textual feature or metadatum ... on the contrary!
Taming the TEI
The TEI offers a choice of over 450 different elements ... we will use (and our schema will only permit) about thirty.
The TEI is very flexible in the structures and perspectives it supports. We will apply Occam's razor extensively.
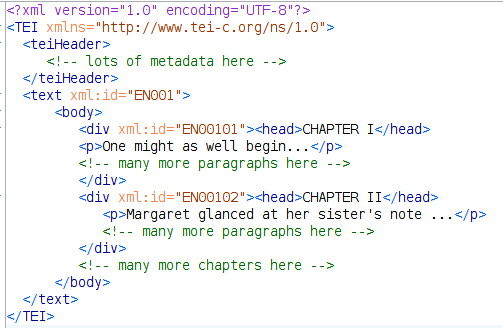
Basic structure of an ELTeC text
Goal : represent only what is essential to an understanding of the text
What are the essential components of a novel?
It seems uncontroversial to distinguish in our markup chapters, headings, paragraphs but how about :
- title page ?
- preface or introduction ?
- table of contents ?
- appendix or afterword ?
- footnotes or comments ?
- errata lists ?
It's not hard to find TEI tags for these: but is it helpful? can we be consistent in their application ?
TEI encoding typically loses typographic subtleties
Are we bothered?
- the chapter title is centred
- there are linebreaks within the paragraphs (and sometimes words get hyphenated as a result)
- the first word is capitalised
- paragraphs are indented (except for the first)
- dash and quote marks have narrative function
- hyphens may or may not be significant
- double quotes and single quotes have different functions
Which typographic features should we keep ?

Figure 1. (Penguin, 1970)

Figure 2. (Knopf, 1921)

Figure 4. (First US ed, 1910)
What about material other than running prose and dialogue ?
Novels often contain material other than running prose
We could:
- use the appropriate TEI elements for verse or drama (<lg>, <l>, <sp>, <stage>)
- use the appropriate TEI elements for lists and tables (<list>, <label>, <item>, <table>, <cell>, <row>)
- use the appropriate TEI elements for graphics (<figure>, <graphic>, <head>)
Or we could
- suppress non-prose material, replacing it by <gap>
- lie
Whichever we choose to do, we must be consistent!
An example
Should this be encoded as:
<p>
<label>le vieillard.</label>
« Oh mon ami ! ne m’avez-vous pas dit que vous
n’aviez pas de naissance ?
</p>
or (expensively)
<sp>
<speaker>le vieillard.</speaker>
<p>« Oh mon ami ! ne m’avez-vous pas dit que
vous n’aviez pas de naissance ?</p>
</sp>
or (deceitfully)
<p>le vieillard.</p>
<p>« Oh mon ami ! ne m’avez-vous pas dit que
vous n’aviez pas de naissance ?</p>
Another example
Should this be encoded as:
<p> Even in her photographic days she had relied upon her smile and her figure to
attract, and now that she was <quote>
<l>"On the shelf,</l>
<l>On the shelf,</l>
<l>Boys, boys, I'm on the shelf,"</l>
</quote> she was not likely to find her tongue. Occasional bursts of song (of
which the above is an example) still issued from her lips, but the spoken word
was rare. </p>
or (deceitfully)
<p>... and now that she was</p>
<p>"On the shelf,
<lb/>On the shelf,
<lb/>Boys, boys, I'm on the shelf,"</p>
<p>she was not likely to find her tongue. Occasional ...</p>
Some other open questions
- should we capture page breaks in our source edition?
- should we remove/resolve end of line hyphenation?
- should we try to interpret typographic variation (italics, etc.) e.g. as <title> <emph> <foreign> <abbr>?
- should we capture (using <hi>) typographic features (and if so should we use rend or style...
- or should we just ignore them ?
Again, consistency of practice is essential. Whether we decide to drop or to preserve these features, we must do so for every text.
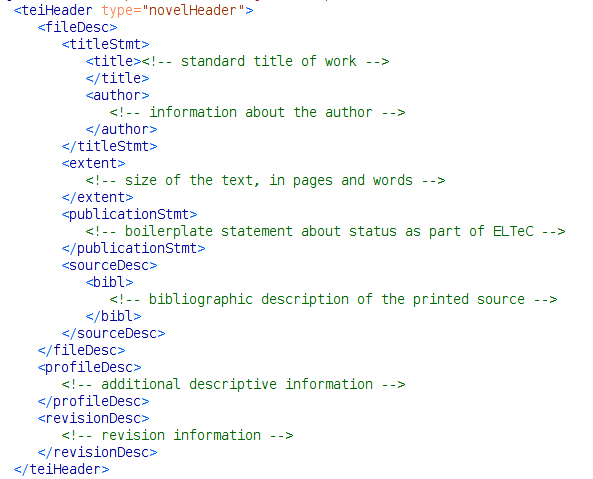
Metadata : the TEI Header
We propose using this for all metadata. It will provide for each text
- bibliographic information
- sampling and descriptive criteria applicable
- housekeeping information
The schema will check consistency of data supplied.
A possible title statement
We may need to modify the TEI definitions
<titleStmt>
<title>Howards End : ELTeC edition</title>
<author dates="1879 1970" sex="M">
<persName>
<forename>Edward</forename>
<forename>Morgan</forename>
<surname>Forster</surname>
</persName>
<persName>E.M. Forster</persName>
<idno type="viaf">https://viaf.org/viaf/31996364</idno>
<idno type="wiki">https://www.wikidata.org/wiki/Q189119</idno>
</author>
<respStmt>
<resp>ELTeC encoding</resp>
<name>Lou Burnard</name>
</respStmt>
</titleStmt>
An example source description
<sourceDesc>
<bibl>
<author>E.M. Forster</author>
<title>Howards End</title>
<pubPlace>London</pubPlace>
<publisher>Edward Arnold</publisher>
<date>1910</date>
<idno type="wiki">https://www.wikidata.org/wiki/Q1146642</idno>
</bibl>
<bibl>
<title>The Project Gutenberg Etext of Howards End, by E. M. Forster</title>
<ref target="http://www.gutenberg.org/files/2891/2891-h/2891-h.htm">HTML
version downloaded on <date>2017-12-26</date>
</ref>
</bibl>
<note type="editions" source="worldcat"> Worldcat lists 484 print editions in
English</note>
</sourceDesc>
And finally... profile and revision descriptions
<profileDesc>
<langUsage>
<language ident="en-BR" usage="99">British English</language>
<language ident="de" usage="1">German</language>
</langUsage>
<textClass>
<keywords source="http://wikidata.org">
<term>social class</term>
<term>social convention</term>
<term>modernity</term>
<term>family drama</term>
</keywords>
<catRef target="#author_m #reprint_3"/>
<classCode scheme="UDC">8231.111</classCode>
</textClass>
</profileDesc>
The values supplied by target are defined in a project-wide <taxonomy>; this and other project-wide metadata is held in a separate corpus header.
<revisionDesc>
<change when="2018-02-11" who="LB">Added to EN collection</change>
</revisionDesc>
Just one small question...
How do we get there from here?
- some, but by no means all, the titles we would like to include may already be available in digital form
- we can automatically (more or less) convert from other TEI vocabs, HTML, ePub, text to our target encoding
- (this may involve removing markup!)
- we need to investigate effectiveness of OCR for other materials
- syntactic validation of the result can be automated
- ... but determining whether or not we are correctly representing a specific text is another matter